

: A Novel Post-Training Quantization Method")

Post-training quantization (PTQ) aims to diminish the size and enhance the speed of substantial language models (LLMs) to render them more applicable for practical usage. Such models necessitate considerable volumes of data; however, significantly skewed and highly diverse data distribution during quantization poses substantial challenges. This invariably broadens the quantization range, resulting in a less precise representation in most values and a decrease in overall model accuracy. Although PTQ methods strive to mitigate these concerns, difficulties persist in effectively distributing data throughout the entire quantization spectrum, restricting opportunities for optimization and obstructing wider implementation in resource-limited settings.
Currently, Post-training quantization (PTQ) techniques for large language models (LLMs) concentrate on weight-only and weight-activation quantization. Weight-only approaches, including GPTQ, AWQ, and OWQ, endeavor to lessen memory consumption by reducing quantization inaccuracies or addressing activation outliers, yet they do not fully optimize accuracy for all values. Methods like QuIP and QuIP# employ random matrices and vector quantization but still face limitations in managing extreme data distributions. Weight-activation quantization seeks to accelerate inference by quantizing both weights and activations. Nonetheless, strategies such as SmoothQuant, ZeroQuant, and QuaRot struggle to cope with the prevalence of activation outliers, leading to inaccuracies in the majority of values. In summary, these techniques depend on heuristic methods and do not optimize the data distribution across the entire quantization range, which restricts performance and effectiveness.
To tackle the shortcomings of heuristic post-training quantization (PTQ) techniques and the absence of a metric for evaluating quantization efficiency, researchers from Houmo AI, Nanjing University, and Southeast University introduced the Quantization Space Utilization Rate (QSUR) concept. QSUR quantifies how efficiently weight and activation distributions leverage the quantization space, providing a metric that can be used to assess and refine PTQ methods. This metric utilizes statistical properties such as eigenvalue decomposition and confidence ellipsoids to compute the hypervolume of weight and activation distributions. QSUR evaluation illustrates how linear and rotational transformations influence quantization efficiency, with specific methodologies reducing inter-channel disparities and minimizing outliers to improve performance.
The researchers introduced the OSTQuant framework, which merges orthogonal and scaling transformations to optimize the weight and activation distributions of large language models. This method amalgamates learnable equivalent transformation pairs of diagonal scaling and orthogonal matrices, ensuring computational efficiency while retaining equivalence during quantization. It diminishes overfitting without compromising the output of the original network during inference. OSTQuant employs inter-block learning to transmit transformations globally across LLM segments, utilizing techniques like Weight Outlier Minimization Initialization (WOMI) for effective initialization. This methodology yields higher QSUR, minimizes runtime overhead, and boosts quantization performance in LLMs.
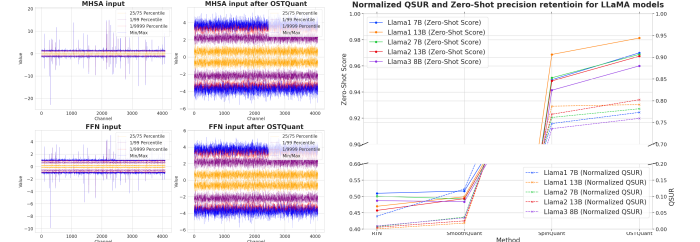
For assessment, researchers applied OSTQuant to the LLaMA series (LLaMA-1, LLaMA-2, and LLaMA-3) and evaluated performance through perplexity on WikiText2 and nine zero-shot tasks. When compared to techniques such as SmoothQuant, GPTQ, Quarot, and SpinQuant, OSTQuant consistently surpassed them, attaining at least 99.5% floating-point precision under the 4-16-16 configuration and considerably narrowing performance gaps. LLaMA-3-8B experienced merely a 0.29-point decline in zero-shot tasks, whereas others faced losses greater than 1.55 points. In challenging scenarios, OSTQuant outperformed SpinQuant and gained as much as 6.53 points with LLaMA-2 7B in the 4-4-16 setup. The KL-Top loss function enhanced the fitting of semantics and reduced noise, leading to improved performance and a 32% reduction in gaps in the W4A4KV4. These results demonstrated that OSTQuant is more effective at dealing with outliers and ensuring that distributions are more equitable.


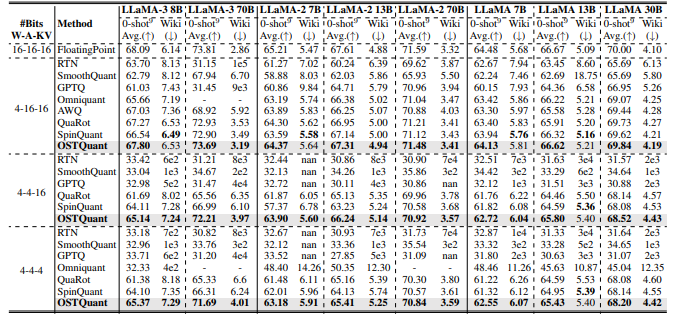
Ultimately, the proposed methodology optimized the data distributions within the quantization space based on the QSUR metric and the KL-Top loss function, thus enhancing the performance of large language models. With minimal calibration data, it reduced noise and maintained semantic depth in comparison to existing quantization approaches, achieving high effectiveness across multiple benchmarks. This framework can lay the foundation for future endeavors, initiating a process vital for refining quantization methodologies and increasing model efficiency for applications necessitating high computational efficiency in resource-limited contexts.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t forget to join our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)
Divyesh serves as a consulting intern at Marktechpost. He is currently studying for a BTech in Agricultural and Food Engineering at the Indian Institute of Technology, Kharagpur. An enthusiast in Data Science and Machine Learning, he aims to incorporate these advanced technologies within the agricultural sector to address various challenges.



Be the first to comment