Chinese AI scholars have accomplished what many believed was eons away: An unrestricted, open-source AI framework that can match or surpass the capabilities of OpenAI’s leading reasoning models. What renders this achievement even more astonishing is the method employed: allowing the AI to learn independently through trial and error, mirroring human learning.
“DeepSeek-R1-Zero, a model refined through extensive reinforcement learning (RL) without supervised fine-tuning (SFT) as an initial phase, exhibits extraordinary reasoning skills,” states the research document.
“Reinforcement learning” refers to a technique where a model receives rewards for making sound choices and penalties for poor ones, without any initial indications of which is which. Over a series of selections, it learns to identify a path that was positively reinforced by those outcomes.
At the outset, during the supervised fine-tuning stage, a team of individuals instructs the model regarding the preferred output they seek, providing it the necessary context to discern what is satisfactory and what isn’t. This leads into the next step, Reinforcement Learning, where a model proposes various outputs and humans assess the top choices. This cycle is repeated incessantly until the model can reliably deliver acceptable results.
Image: Deepseek
DeepSeek R1 is a milestone in AI advancement due to the minimal involvement of humans in the training process. In contrast to other models that rely on extensive supervised data, DeepSeek R1 primarily learns through mechanical reinforcement learning—essentially discovering solutions by testing and receiving feedback on what succeeds.
“Through RL, DeepSeek-R1-Zero intrinsically manifests numerous potent and intriguing reasoning capabilities,” the investigators mentioned in their publication. The model even cultivated advanced skills such as self-verification and reflection without being explicitly coded to achieve such outcomes.
As the model progressed through its training, it instinctively learned to dedicate more “thinking time” to intricate challenges and acquired the skill to recognize its own errors. The researchers noted a pivotal “a-ha moment” where the model learned to reassess its original strategies for tackling issues—an ability it was not specifically programmed to possess.
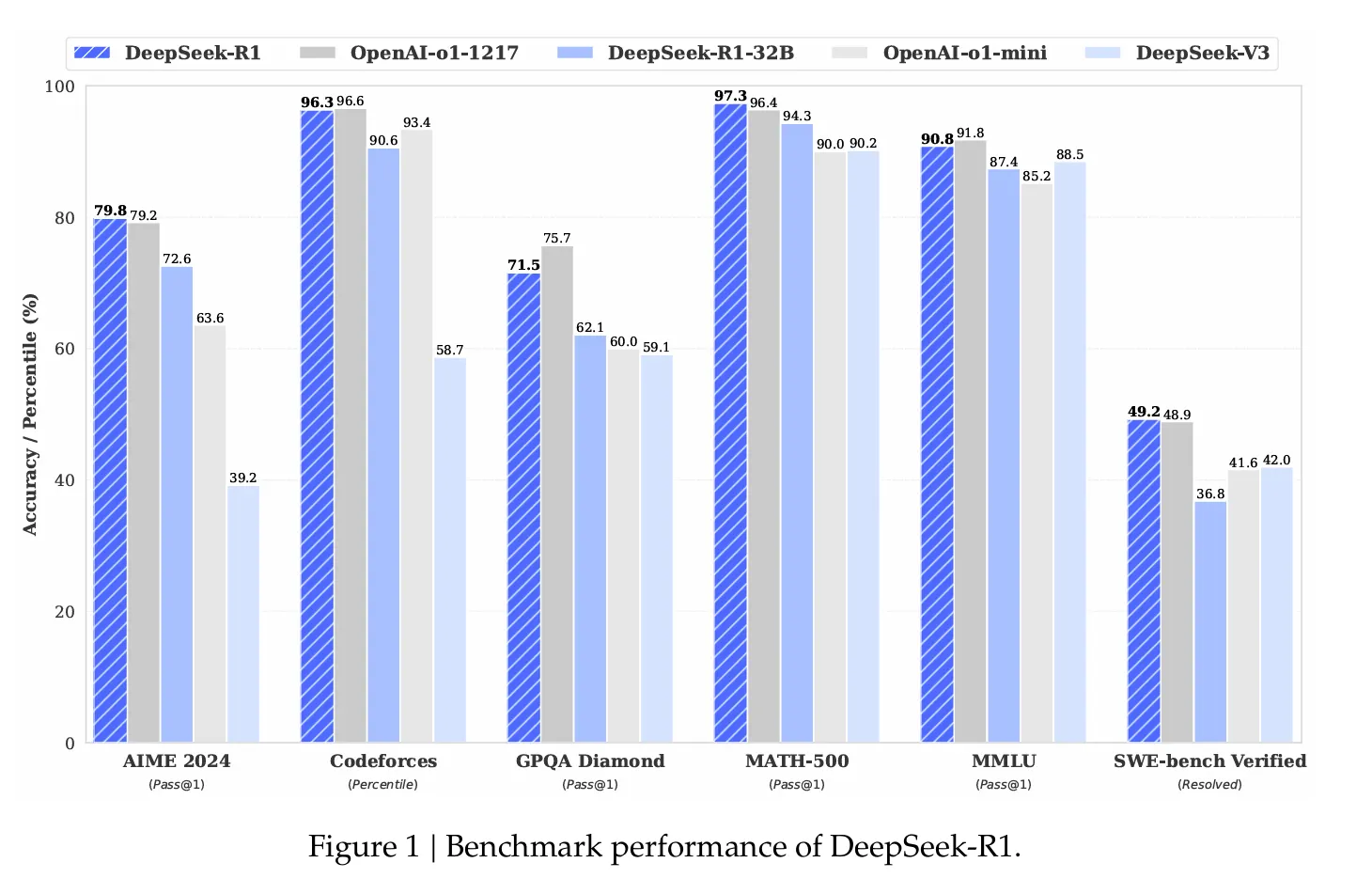
The results are noteworthy. On the AIME 2024 mathematics evaluation, DeepSeek R1 attained a 79.8% success rate, outpacing OpenAI’s o1 reasoning framework. On standardized coding assessments, it exhibited “expert level” proficiency, achieving a 2,029 Elo rating on Codeforces and outperforming 96.3% of human contenders.
“`html Image: Deepseek
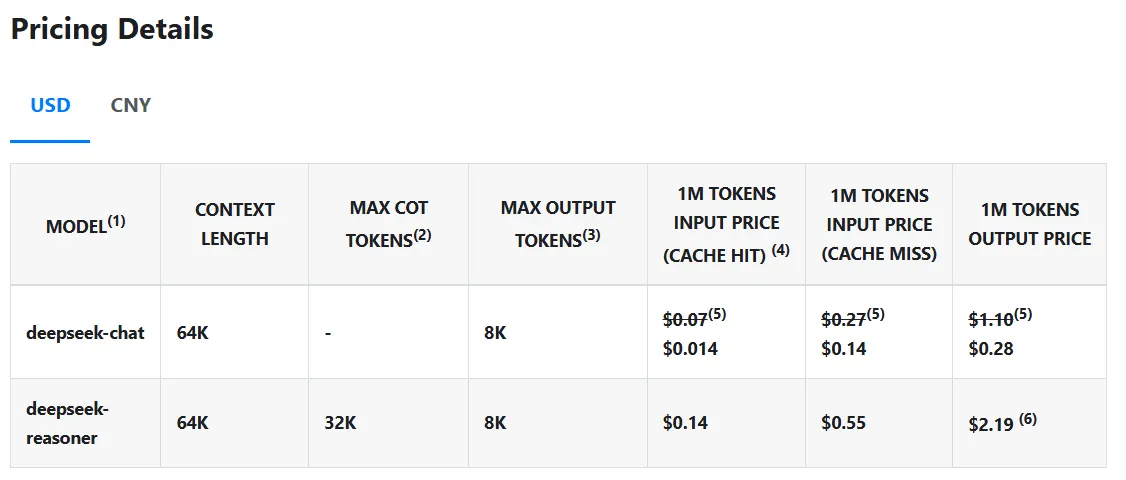
However, what truly distinguishes DeepSeek R1 is its affordability—or rather, the absence of it. This model executes queries at merely $0.14 per million tokens, in stark contrast to OpenAI’s $7.50, rendering it 98% less expensive. Additionally, unlike commercial models, the code and training techniques of DeepSeek R1 are entirely open-source under the MIT license, allowing anyone to acquire the model, utilize it, and modify it freely.
Image: Deepseek
Responses from AI leaders
The introduction of DeepSeek R1 has provoked a flood of reactions from leaders within the AI domain, many of whom underscore the importance of an entirely open-source model equaling proprietary frontrunners in reasoning skills.
Dr. Jim Fan, a leading researcher at Nvidia, provided perhaps the most incisive critique, establishing a direct correlation with OpenAI’s foundational goal. “We are inhabiting a timeline where a non-U.S. firm is preserving the original mission of OpenAI—authentically open frontier research that empowers everyone,” remarked Fan, commending DeepSeek’s unparalleled transparency.
We are living in a timeline where “`a non-US organization is preserving the foundational purpose of OpenAI – genuinely open, pioneering exploration that enables everyone. It seems illogical. The most captivating result is the most probable.
DeepSeek-R1 not only liberates a multitude of models but… pic.twitter.com/M7eZnEmCOY
— Jim Fan (@DrJimFan) January 20, 2025
Fan highlighted the importance of DeepSeek’s reinforcement learning methodology: “They might be the inaugural [open source software] initiative demonstrating considerable sustained advancement of [a reinforcement learning] flywheel.” He also praised DeepSeek’s clear provision of “raw algorithms and matplotlib learning curves” in contrast to the hype-laden announcements prevalent in the sector.
Apple researcher Awni Hannun noted that individuals can execute a quantized variant of the model locally on their Macs.
DeepSeek R1 671B operating on 2 M2 Ultras faster than reading speed.
Approaching open-source O1, at home, on consumer-grade hardware.
With mlx.distributed and mlx-lm, 3-bit quantization (~4 bpw) pic.twitter.com/RnkYxwZG3c
— Awni Hannun (@awnihannun) January 20, 2025
Historically, Apple devices have struggled with AI because of their incompatibility with Nvidia’s CUDA software, but that seems to be shifting. For instance, AI researcher Alex Cheema managed to run the complete model after leveraging the capabilities of 8 Apple Mac Mini units working in unison—which is still less expensive than the servers needed to operate the most powerful AI models available today.
Despite that, users can run lighter versions of DeepSeek R1 on their Macs with satisfactory levels of accuracy and efficiency.
However, the most intriguing responses arose when reflecting on how close the open-source sector is to proprietary models, and the possible repercussions this development could have for OpenAI as the dominant entity in the realm of reasoning AI models.
Stability AI’s founder Emad Mostaque adopted a bold perspective, positing that the release pressures better-capitalized rivals: “Can you imagine being a frontier lab that’s raised around a billion dollars and now you can’t unveil your latest model because it can’t outperform DeepSeek?”
Can you imagine being a “frontier” lab that’s raised around a billion dollars and now you can’t unveil your latest model because it can’t surpass DeepSeek? 🐳
Sota can be tough if that’s your aim
— Emad (@EMostaque) January 20, 2025
Utilizing a similar line of reasoning but with more serious implications, tech entrepreneur Arnaud Bertrand articulated that the rise of a competitive open-source model may detrimentally affect OpenAI, as it renders its models less alluring to power users who may otherwise consider investing significantly per task.
“It’s essentially akin to someone releasing a mobile phone comparable to the iPhone, but selling it for $30 instead of $1000. It’s that significant.”
Most people probably don’t grasp how detrimental news China’s Deepseek is for OpenAI.
They’ve developed a model that matches and even surpasses OpenAI’s latest model o1 on several benchmarks, and they’re pricing it at merely 3% of the cost.
It’s practically as if someone had introduced a… pic.twitter.com/aGSS5woawF
— Arnaud Bertrand (@RnaudBertrand) January 21, 2025
Perplexity AI’s CEO Arvind Srinivas articulated the release concerning its market effect: “DeepSeek has mainly duplicated o1 mini and has made it open-source.” In a subsequent comment, he remarked on the rapid advancement: “It’s kind of astonishing to witness reasoning being commodified this swiftly.”
It’s quite astonishing to see reasoning being commodified this swiftly. We should fully anticipate an o3 level model that’s open-sourced by the year’s end, probably even mid-year. pic.twitter.com/oyIXkS4uDM
— Aravind Srinivas (@AravSrinivas) January 20, 2025
Srinivas mentioned that his team aims to integrate DeepSeek R1’s reasoning capabilities into Perplexity Pro in the future.
Quick hands-on
We conducted a few quick assessments to compare the model against OpenAI o1, beginning with a popular question for such benchmarks: “How many Rs are in the word Strawberry?”
Typically, models find it challenging to deliver the correct response since they don’t work with words—they process tokens, digital representations of concepts.
GPT-4o was unsuccessful, OpenAI o1 succeeded—and DeepSeek R1 did as well.
However, o1 was very succinct in the reasoning process, while DeepSeek produced an extensive reasoning output. Interestingly, DeepSeek’s response felt more human-like. During its reasoning, the model seemed to converse with itself, employing slang and terms that are unusual for machines but more commonly used by humans.
For instance, while contemplating the number of Rs, the model mused to itself, “Alright, let me deduce this.” It also expressed “Hmmm” during its deliberation, and even remarked, “Hold on, no. Wait, let’s analyze it.”
The model ultimately arrived at the accurate conclusions, but invested considerable time reasoning and generating tokens. Under standard pricing circumstances, this would present a drawback; however, considering the present situation, it can produce significantly more tokens than OpenAI o1 while remaining competitive.
Another evaluation to gauge the models’ reasoning capabilities involved playing “spies” to identify the culprits in a brief narrative. We selected a sample from the BIG-bench dataset on Github. (The complete story is accessible here and entails a school excursion to a secluded, snow-laden site, where students and educators encounter a sequence of bizarre disappearances, and the model must uncover who the stalker is.)
Both models deliberated for over one minute. Nevertheless, ChatGPT failed before unraveling the enigma:
However, DeepSeek provided the correct response after “contemplating” for 106 seconds. The reasoning process was accurate, and the model even managed to rectify its errors after arriving at incorrect (yet still sufficiently logical) deductions.
The availability of smaller iterations particularly amazed researchers. To put it in perspective, a 1.5B model is so compact that one could theoretically run it on a high-performance smartphone. Moreover, even a quantized version of Deepseek R1 that small could compete on equal footing with GPT-4o and Claude 3.5 Sonnet, according to Hugging Face’s data analyst Vaibhav Srivastav.
“DeepSeek-R1-Distill-Qwen-1.5B surpasses GPT-4o and Claude-3.5-Sonnet in math assessments with 28.9% on AIME and 83.9% on MATH.”
— Vaibhav (VB) Srivastav (@reach_vb) January 20, 2025
Just a week prior, UC Berkeley’s SkyNove unveiled Sky T1, a reasoning model also capable of competing against OpenAI o1 preview.
Those keen on executing the model locally can obtain it from Github or Hugging Face. Users have the option to download it, run it, eliminate censorship, or customize it for different fields of expertise through fine-tuning.
Alternatively, if you wish to test the model online, visit Hugging Chat or DeepSeek’s Web Portal, which serves as an excellent alternative to ChatGPT—especially since it’s free, open-source, and the sole AI chatbot interface with a model designed for reasoning aside from ChatGPT.
Edited by Andrew Hayward
Generally Intelligent Newsletter
A weekly exploration of AI narrated by Gen, a generative AI model.
One of the leading companies in graphics technology today is NVIDIA. Zach Anderson Jan 17, 2025 14:11 NVIDIA introduces new KV cache optimizations in TensorRT-LLM, enhancing performance and efficiency for large language models on GPUs […]
Terrill Dicki Jan 22, 2025 11:24 Investigate the advancement and critical insights gleaned from NVIDIA’s AI sales assistant, utilizing large language models and retrieval-augmented generation to optimize sales procedures. NVIDIA has established itself as a […]
Subscribe to our daily and weekly newsletters for the most recent updates and exclusive content on premier AI coverage in the industry. Learn More When Anthropic’s CEO Dario Amodei asserted that AI would generate 90% […]







Be the first to comment